1. Window Function?
1) 개요
(1) 행과 행간의 관계를 쉽게 정의하기 위해 제공되는 함수
(2) 분석함수 또는 순위함수로도 불림
(3) 기존의 집계함수 또한 window function으로 통합됨
(4) 서브쿼리 사용 가능함
(5) 기본 문법

2) 종류
(1) AVG : Null 값을 무시한 평균을 반환
SELECT SalesOrderID
, SalesOrderDetailID
, ProductID
, UnitPrice
, AVG(UnitPrIce) OVER(
PARTITION BY SalesOrderID
) AS AvgUnitPrIce
, AVG(UnitPrIce) OVER(
PARTITION BY SalesOrderID
ORDER BY SalesOrderDetailID
) AS MoveAvgUnitPrIce
FROM AdventureWorks2019.Sales.SalesOrderDetail
위와 같이 window function을 이용하면 위와 같이 다른 컬럼들과 같이 사용되어 내용을 출력할 수 있다.
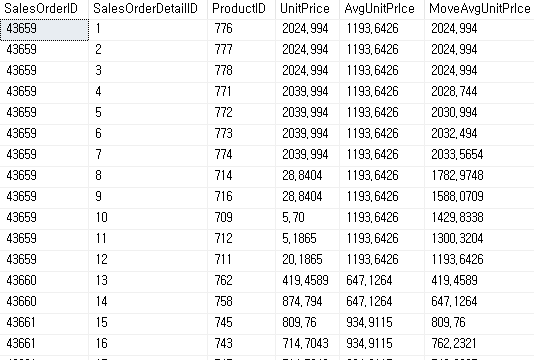
위에 결과 표를 확인하면 AvgUnitPrice(Partition by 만 사용)과 MoveAvgUnitPrice(Partition by와 Order by 사용)의 차이를 구분할 수 있는데
Partition by절만 사용하면 해당 전체의 평균을 구하고 Order by절을 사용하면 정렬되어 해당 행까지의 평균을 값을 구하는 것을 알 수 있다.
(2) COUNT : 해당 항목의 개수를 반환
SELECT SalesOrderID
, SalesOrderDetailID
, ProductID
, UnitPrice
, COUNT(UnitPrIce) OVER(
PARTITION BY SalesOrderID
) AS UnitPriceCnt
, COUNT(UnitPrIce) OVER(
PARTITION BY SalesOrderID
ORDER BY SalesOrderDetailID
) AS MoveUnitPriceCnt
FROM AdventureWorks2019.Sales.SalesOrderDetail
SELECT SalesOrderID
, COUNT(DISTINCT UnitPrIce) AS AvgUnitPrIce
FROM AdventureWorks2019.Sales.SalesOrderDetail
GROUP BY SalesOrderID
ORDER BY SalesOrderID
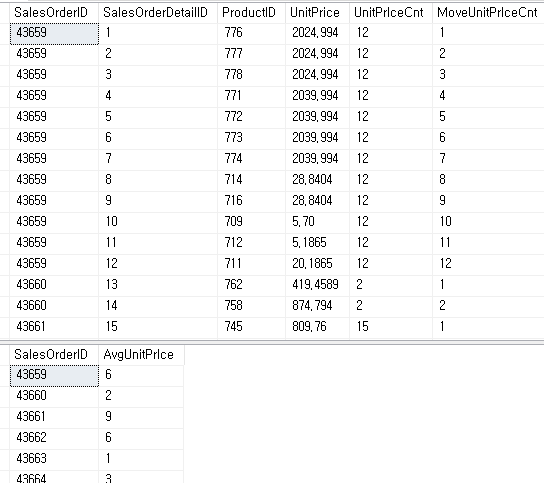
UnitPriceCnt(Partition by만 사용) 해당 항목의 전체 개수를 반환하고 MoveUnitPriceCnt는 (Partition by 와 order by 사용) 데이터를 정렬하고 해당 행까지의 개수를 반환 하는 것을 확인할 수 있다.
OVER절을 사용하게 되면 DISTINCT를 사용할 수 없게 되는데 DISTINCT는 해당 컬럼의 값의 NULL을 제외한 유니크한 값을 추출하는 명령어이다.
(3) COUNT_BIG : COUNT 함수와 같으나 반환되는 자료형이 BIGINT
(4) MAX : 항목의 최대값을 반환
SELECT SalesOrderID
, SalesOrderDetailID
, ProductID
, UnitPrice
, MAX(UnitPrIce) OVER(
PARTITION BY SalesOrderID
) AS MaxUnitPrice
, MAX(UnitPrIce) OVER(
PARTITION BY SalesOrderID
ORDER BY UnitPrice
) AS MaxMoveUnitPrice
FROM AdventureWorks2019.Sales.SalesOrderDetail
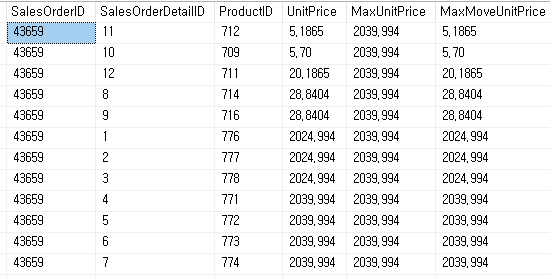
MaxUnitPrice (Partition by만 사용) 해당 항목의 최대값을 반환하고 MaxMoveUnitPrice는 (Partition by 와 order by 사용) 데이터를 정렬하고 해당 행까지의 최대값을 반환 하는 것을 확인할 수 있다.
(5) MIN : 항목의 최소값을 반환
SELECT SalesOrderID
, SalesOrderDetailID
, ProductID
, UnitPrice
, MIN(UnitPrIce) OVER(
PARTITION BY SalesOrderID
) AS MinUnitPrice
, MIN(UnitPrIce) OVER(
PARTITION BY SalesOrderID
ORDER BY UnitPrice DESC
) AS MinMoveUnitPrice
FROM AdventureWorks2019.Sales.SalesOrderDetail
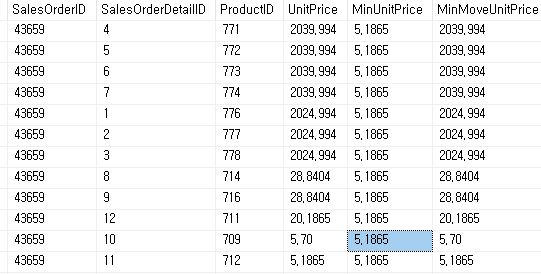
MinUnitPrice (Partition by만 사용) 해당 항목의 최소값을 반환하고 MinMoveUnitPrice는 (Partition by 와 order by 사용) 데이터를 정렬하고 해당 행까지의 최소값을 반환 하는 것을 확인할 수 있다.
(6) STDEV : 해당 항목 중 표본의 통계적 표준 편차를 반환
SELECT SalesOrderID
, SalesOrderDetailID
, ProductID
, UnitPrice
, STDEV(UnitPrIce) OVER(
PARTITION BY SalesOrderID
) AS StdevUnitPrice
, STDEV(UnitPrIce) OVER(
PARTITION BY SalesOrderID
ORDER BY UnitPrice DESC
) AS StdevMoveUnitPrice
FROM AdventureWorks2019.Sales.SalesOrderDetail
StdevUnitPrice (Partition by만 사용) 해당 항목의 표준편차를 반환하고 StdevMoveUnitPrice는 (Partition by 와 order by 사용) 데이터를 정렬하고 해당 행까지의 표준편차를 반환 하는 것을 확인할 수 있다.
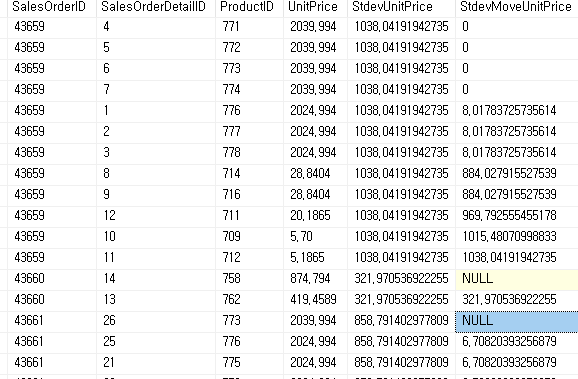
표본 표준 편차는 n-1로 값을 나누기 때문에 해당 행이 1인 행의 값을 구할 수 없기 때문에 null 반환되지만 정렬의 첫 번째(최소 또는 최대값) 값이 중복될 경우 2개 이상의 행을 가지기 때문에 0의 값을 가진다.
(7) STDEVP : STDEV와 같으나 모집단 전체의 표준 편차
SELECT Rdata.SalesOrderID
, SQRT(SUM(
POWER(Rdata.UnitPrice - Acc.AvgPrice,2)
)/Acc.CNT) AS StdevpValue
, SQRT(SUM(
POWER(Rdata.UnitPrice - Acc.AvgPrice,2))
/(Acc.CNT-1)) AS StdevValue
FROM (
SELECT SalesOrderID
, AVG(UnitPrice) AS AvgPrice
, COUNT(UnitPrice) AS Cnt
FROM AdventureWorks2019.Sales.SalesOrderDetail
GROUP BY SalesOrderID
) AS Acc
INNER JOIN AdventureWorks2019.Sales.SalesOrderDetail AS Rdata
ON Acc.SalesOrderID = Rdata.SalesOrderID
GROUP BY Rdata.SalesOrderID, Acc.CNT
ORDER BY Rdata.SalesOrderID
(8) SUM : 항목의 null을 무시한 값의 합
SELECT SalesOrderID
, SalesOrderDetailID
, ProductID
, UnitPrice
, SUM(UnitPrIce) OVER(
PARTITION BY SalesOrderID
) AS StdevUnitPrice
, SUM(UnitPrIce) OVER(
PARTITION BY SalesOrderID
ORDER BY UnitPrice ASC
) AS StdevMoveUnitPrice
FROM AdventureWorks2019.Sales.SalesOrderDetail
Order by를 통한 해당 행까지의 부분합을 구할 수 있다.
(9) VAR : 해당 항목 표본의 분산
SELECT SalesOrderID
, SalesOrderDetailID
, ProductID
, UnitPrice
, VAR(UnitPrIce) OVER(
PARTITION BY SalesOrderID
) AS VarUnitPrice
, VAR(UnitPrIce) OVER(
PARTITION BY SalesOrderID
ORDER BY UnitPrice ASC
) AS VarMoveUnitPrice
FROM AdventureWorks2019.Sales.SalesOrderDetail
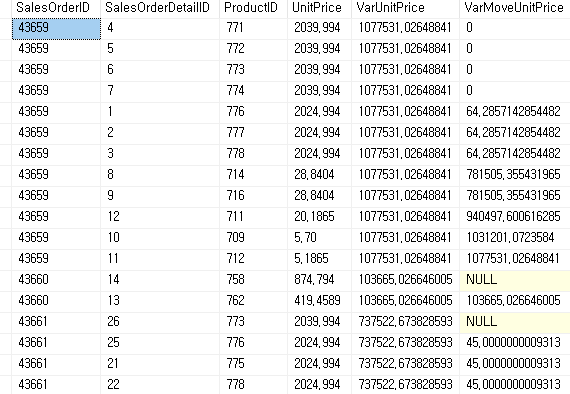
STDEV(표본 표준 편차)와 마찬가지로 (N-1)개의 행으로 나누기 때문에 NULL 값에 대한 반환이 0과 NULL로 나뉘어 반환된다.
(10) VARP : 항목의 모집단 전체의 분산
SELECT Rdata.SalesOrderID
, SUM(
POWER(Rdata.UnitPrice - Acc.AvgPrice,2)
)/Acc.CNT AS VarpValue
, SUM(
POWER(Rdata.UnitPrice - Acc.AvgPrice,2))
/(Acc.CNT-1) AS VarValue
FROM (
SELECT SalesOrderID
, AVG(UnitPrice) AS AvgPrice
, COUNT(UnitPrice) AS Cnt
FROM AdventureWorks2019.Sales.SalesOrderDetail
GROUP BY SalesOrderID
) AS Acc
INNER JOIN AdventureWorks2019.Sales.SalesOrderDetail AS Rdata
ON Acc.SalesOrderID = Rdata.SalesOrderID
WHERE Acc.CNT > 1
GROUP BY Rdata.SalesOrderID, Acc.CNT
ORDER BY Rdata.SalesOrderID
2. 출처
'Database > SQL Server' 카테고리의 다른 글
| SQL Server 인스턴스 데이터 정렬(Collation) 변경 (0) | 2021.08.20 |
|---|---|
| window function(분석) (0) | 2021.08.17 |
| window function(순위, 순서, 분산) (0) | 2021.08.17 |
| Visual code on SQL server (0) | 2021.07.02 |
| ISNULL, COALESCE, CASE, NULLIF 그리고 SIGN (0) | 2021.06.01 |






최근댓글