1. 파리프라인을 통한 테이터 이관 및 ETL, 스케줄 PaaS 서비스
2. 데이터 셋을 저장하여 연결을 재사용
3. Dataflow를 이용한 PaaS형 ETL 작업 사용 가능
4. Databricks등과 연계하여 복잡한 ETL 작업 및 분석을 관리할 수 있음
5. 다양한 트리거를 통한 작업 가능
6. 리소스 관리
1) 해당 연필 모양의 UI 버튼을 통해 접근
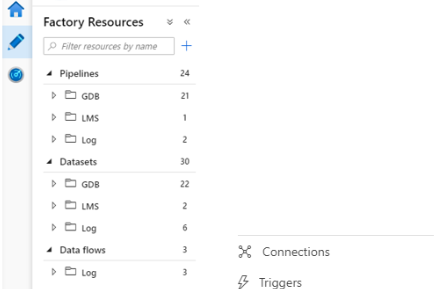
2) Pipeline : 작업의 순서를 관리하고 발생 트리거를 관리
3) Datasets : 원본 데이터 및 가공 후 저장하는 데이터를 관리한다.
4) Data flows : Azure에서 제공하는 PaaS형 ETL로 기본 Spark Node를 이용한다.
5) Connections : Datasets에서 사용되는 DB 및 파일들의 연결을 관리
6) Triggers : Pipeline이 실행되는 방법들을 관리
7. 디버깅 및 소스 관리

1) 해당 작업을 Publish 및 Discard로 저장 및 취소 관리된다.
2) Publish는 객체 별이 아닌 ALL 형태로 저장해야 하기 때문에 객체 작업 하나 완료 후엔 무조건 Publish 해주는 것이 좋다.
3) Data flow Debug 옵선을 통해 데이터 변환을 임시적으로 확인 가능
4) Debug의 Intergration runtime(IR)은 Azure용 AutoResolve만 사용 가능하다.
'Cloud > Azure' 카테고리의 다른 글
| Azure Data Factory - Data Flow (0) | 2021.04.20 |
|---|---|
| Azure Data Factory - Datasets (0) | 2021.04.20 |
| Azure Data Factory - Pipeline (0) | 2021.04.19 |
| Azure Storage Account (0) | 2021.04.19 |
| Azure Resource Group & Azure Active Directory (0) | 2021.04.16 |








최근댓글