1. 작업의 순서를 관리하고 작업들을 해당 pipe 순서에 맞게 실행한다.
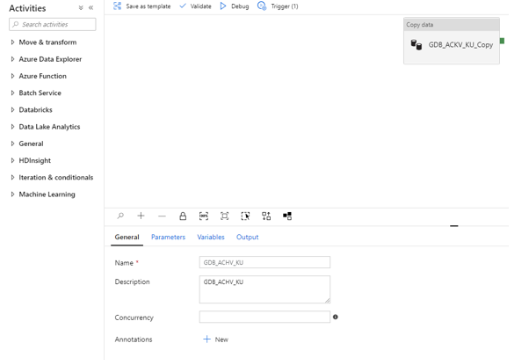
1) General : Pipeline의 이름 및 설명
2) Parameters : Trigger에서 발생되어 Pipeline에 전달된 값
3) Variables : Pipeline에서 사용되는 Global 변수
4) output : Pipeline이 완료되었을 시 해당 값을 return
2. Activities : Pipeline의 동작을 구성
1) Move & transform
A. copy data : 다른 원천 Dataset으로부터 데이터를 복사하여 새로운 Dataset으로 복사

가) General : 작업의 명칭, 설명, timeout 설정, 재시도 횟수 들을 설정할 수 있다.
(ㄱ) Timeout은 일 단위부터 설정 가능하다
(ㄴ) 일.시간:분:초 의 구조
나) Source : 복사할 원본 데이터

(ㄱ) Source dataset : 원본 Dataset
I. new : 새로 생성
II. open : 이미 생성되어 있는 Dataset으로 연결
III. preview data : 정상 연결된 dataset으로 원본 데이터 일부 확인
(ㄴ) Use query : Table 전체를 가져올 것인지 명령어를 사용하여 Query 사용하여 데이터를 가져올 것인지 선택
I. Table 선택 시 : 테이블 전체의 내용을 설정에 따라 가져오게 된다.
II. Query 선택 시
(1) Query 입력 창이 생성된다.
(2) Dataset에서 제공하는 Query 가능한 커넥터면 모두 가능
(3) Ansi SQL 외에도 해당 DB 엔진이 제공하는 형태면 조회 가능하다. (아마 odbc 형태로 연결되는 것이지 않을까 추측해본다.)
다) Sink : Source에서 읽어온 데이터를 어디에 저장할 것인지 설정

(ㄱ) Sink Dataset : 이관되어 저장할 dataset
I. new : 새로 생성
II. open : 기존에 이미 연결해준 dateset에 연결
(ㄴ) Copy behavior : 원본이 파일 기반 저장소일 경우 복사 시 계층 구조 변경
I. PreserveHierarchy(기본값) : 원본의 폴더 구조를 유지
II. FlattenHierarchy : 원본의 파일을 모두 계층 첫번째로 처리
III. MergeFiles : 원본의 파일을 모아 하나로 저장
(ㄷ) Max concurrent connections : 동시 연결 최대값
(ㄹ) Block size (MB) : blob 저장 시의 block의 크기
라) Mapping : 설정하지 않지 않았을 시 원본의 schema를 그대로 저장
마) Setting : 실헹 시 사용될 자원의 셋팅, 기본값은 auto
(ㄱ) Enable Staging : 중간 과정을 blob에 저장함으로써 속도 개선
I. Staging account linked service : 중간과정을 저장할 blob container
II. Storage path : Blob의 저장 주소
III. Enable Compression : 중간 저장 시 압축 여부 결정
바) User Properties : 모니터링 시 모니터에 출력될 값 등의 속성값을 지정할 수 있다.
B. Data Flow : ADF 내에서 작업된 Data Flow를 실행
가) General : 작업의 명칭, 설명, Time out 설정, 재시도 횟수 등을 관리

나) Setting
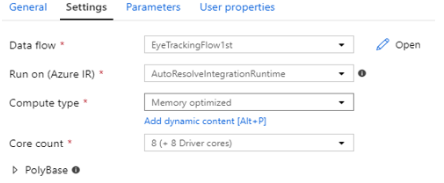
(ㄱ) Data flow : 이미 정의도니 Data Flow를 블러오기
(ㄴ) Run on(Azure IR) : IR을 선택하나 Data flow 는 Azure IR만 지원함 AutoResolveIR을 사용해야 한다.
(ㄷ) Compute Type : IR 옵션 마다 사용 비용이 다름, G < M < C 순
I. general purpose : 일반적인 코어
II. Compute optimized : CPU 집약적 코어
III. Memory optimized : 메모리 집약적 코어
(ㄹ) Core Count : 생성될 IR VM의 Core 크기
(ㅁ) PolybBase : 중간 과정을 디스크에 저장함으로써 속도 개선
I. Staging linked service : 중간과정을 저장할 blob container
II. Storage storage folder : Blob의 저장 주소
다) Parameter : Data flow로 전달될 값
라) User Properties : 모니터링에 남길 속성값
2) Databricks : Azure Databricks에서 진행되는 Spark 작업
A. Notebook : Databricks Workspace에 등록된 Notebook을 등록 실행

가) General : 작업의 명칭, 설명, Time out 설정, 재시도 횟수 등을 관리
나) Azure Databricks : Linked로 이미 연결해둔 Azure Databricks 선택
다) Setting
(ㄱ) Notebook path : 해당 Job에서 실행할 Databricks에 등록되어 있는 Notebook 선택
(ㄴ) Base Parameters : 노트북에 전달될 파라미터 지정
(ㄷ) Append libraries : 추가적으로 추가할 패키지가 있다면 추가
(해당 패키지는 해당 Databricks 클러스터에 추가되어 있어야 함)
(ㄹ) User Properties : 모니터링 시 확인하는 사용자 설정 값
B. Jar : Azure Databricks의 Workspace에 등록되어 있는 Spark Scalar 실행
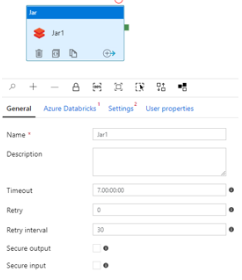
가) General : 작업의 명칭, 설명, Time out 설정, 재시도 횟수 등을 관리
나) Azure Databricks : Linked로 이미 연결해둔 Azure Databricks 선택
다) Setting
(ㄱ) Main Class Name : 실행되는 프로세스의 Main Class 설정
(ㄴ) Parameters : Main Class 에 전달될 파라미터
(ㄷ) Append libraries : 추가적으로 추가할 패키지가 있다면 추가
(해당 패키지는 해당 Databricks 클러스터에 추가되어 있어야 함)
(ㄹ) User Properties : 모니터링 시 확인하는 사용자 설정 값
C. Python : Azure Databricks Workspace에 등록된 Pyspark 파일 실행

가) General : 작업의 명칭, 설명, Time out 설정, 재시도 횟수 등을 관리
나) Azure Databricks : Linked로 이미 연결해둔 Azure Databricks 선택
다) Setting
(ㄱ) Python file : 실행될 python 파일
(ㄴ) Parameters : Python 파일에 전달될 파라미터
(ㄷ) Append libraries : 추가적으로 추가할 패키지가 있다면 추가
(해당 패키지는 해당 Databricks 클러스터에 추가되어 있어야 함)
(ㄹ) User Properties : 모니터링 시 확인하는 사용자 설정 값
3) Iteration & conditionals
A. forEach
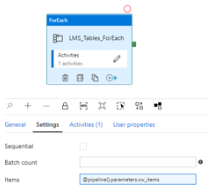
가) General : ForEach 작업명
나) Setting
(ㄱ) Sequential : 순서를 가지는 지 여부
(ㄴ) Batch count : 반복을 횟수로 지정할 수 있음
(ㄷ) Items : 배열 정보를 전달하여 EndPoint 값을 가져올 때 까지 반복 진행
다) Activities : 반복을 진행하면서 수행될 작업

라) User Properties : 모니터링 시 확인하는 사용자 설정 값
B. 그 외
가) filter : 원하는 컬럼만 가져옴
나) if Condition : 조건문에 따라 진행할 Activities 를 분기
다) Switch : 선택문에 따라 진행되는 Activities 지정
라) Until : 반복 조건이 만족도기 전까지 반복 진행되는 Activities 지정
4) 그 외 작업들
A. Azure Data Explorer : Azure 데이터 탐색기로 데이터 이관
B. Azure Function : Azure function을 통한 Lambda 실행
C. Batch Service : Azure Batch를 통한 Batch 스크립트 실행
D. Data Lake Analytics : Azure Data Lake Analytics로 데이터 이관
E. General : Rest API 등 일반적인 작업 통신 작업 들
F. HDInsight : Azure HDInsight의 job을 실행
G. Machine Leaning : Azure ML의 job을 실행
'Cloud > Azure' 카테고리의 다른 글
| Azure Data Factory - Data Flow (0) | 2021.04.20 |
|---|---|
| Azure Data Factory - Datasets (0) | 2021.04.20 |
| Azure Data Factory (ADF) 란? (0) | 2021.04.19 |
| Azure Storage Account (0) | 2021.04.19 |
| Azure Resource Group & Azure Active Directory (0) | 2021.04.16 |








최근댓글