1. ADF내에서 PaaS 형태로 제공하는 ETL툴
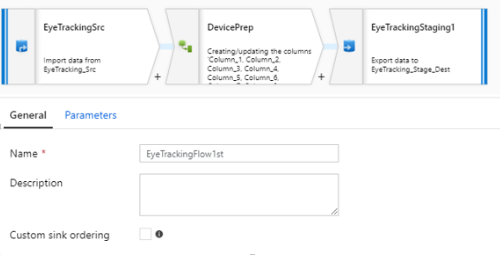
1) 기본적으로 Source -> ETL –> Sink의 기본 구조를 가진다
2) General : 이름, 설명 등 기본 정보
A. Custom Sink ordering : Sink가 여러 개 일 경우 작업 순서 결정
3) Parameter : Data Flow가 실행 전 전달받을 파라미터 값
2. Source
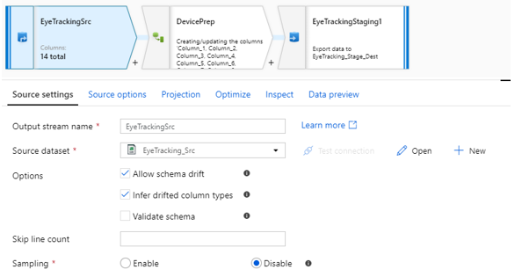
1) Source Setting
A. Output stream name : 해당 작업의 이름
B. Source Dataset : 이미 정의해 놓은 Dataset 선택
C. Option
I. Allow schema drift : 컬럼 변경 허용
II. Infer drifted column types : 변경될 컬럼의 자료형 자동 처리
III. Validate schema : 선언된 schema를 찾을 수 없을 시 실패 처리
D. Skip line count : 행당 수의 행만큼 작업을 진행하지 않음
E. Sampling : Source의 일부만 샘플링하여 처리할 것인지 여부
2) Source options : Data Flow 진행 시 이용될 특이 사항에 대한 설정
3) Projection : Dataset에 의해 자동으로 생성된 schema가 자동으로 선언되나 사용자 정의 형태로 변경 가능
4) Optimize : 사용자가 데이터의 흐름 형태를 선택할 수 있다.
5) Inspect : 예상되는 데이터를 확인 가능
6) Data preview : Data Flow Debug를 통해 사전 데이터를 일부 조회 가능
3. ETL
1) Source의 데이터를 조작하여 Sink로 넘기는 데이터 조작 과정
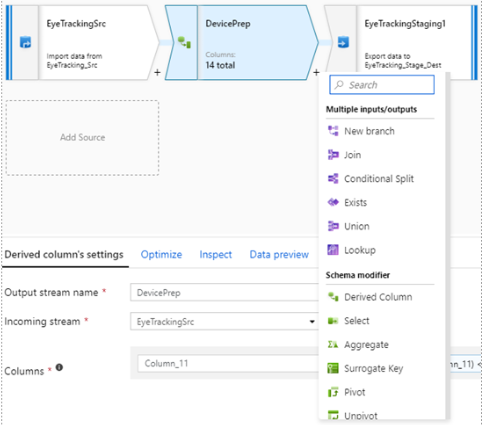
A. Multiple inputs / outputs
I. New branch : 같은 데이터를 분기하여 진행하도록 도와줌
II. Join : 2개의 Source를 조건에 맞는 하나의 데이터로 Join함
III. Conditional Split : 조건에 따라 데이터를 여러 개로 분류 함
IV. Exists : 조건에 포함되거나 조건에 포함된 데이터를 제외한 데이터로 분류
V. Union : 여래 개의 Source를 한 개의 Dataset으로 병합함
VI. Lookup : Key값에 매칭되는 참조테이블로 컬럼 변환
B. Schema modifiter
I. Derived Column : 기존에 존재하는 컬럼을 재가공하여 열 추가 또는 패턴을 추가한다.
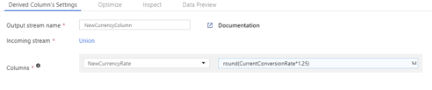
가) Derived Column`s settings
(ㄱ) Output stream name : 작업 이름
(ㄴ) Incoming stream : 해당 작업 이전에 실행된 작업 또는 Source
(ㄷ) Columns : 열 추가 또는 패턴 작업
나) Optimize : 작업 시 데이터 흐름 방식을 정함
(ex> round robin 등)
다) Inspect : 예상되는 결과값
라) Data preview : Data Flow Debug를 통한 사전 데이터 일부 조회
II. Select : Column에 별칭을 정하여 다음 작업 사용
III. Aggregate : 조건 Column에 대해 집계 함수를 사용한 데이터 치환
IV. Surrogate Key : 데이터를 조작하는 가운데 새로운 고유값을 발급
V. Pivot : Row값을 Column명으로 치환
VI. Unpivot : Column명을 Row로 치환
VII. Window : 정령의 번호, Ranking 등의 집계
VIII. Flatten : Json 내부의 배열 값을 rowdata로 분해해 2차원으로 변경
C. row modifiter
I. Filter : SQL WHERE 절과 마찬가지로 데이터 필터링
II. Sort : 수신되는 데이터 정렬
III. Alter Row : 조건에 따라 데이터를 변경 또는 삽입하는 작업
4. Sink
1) ETL을 거쳐 최종적으로 저장되는 데이터
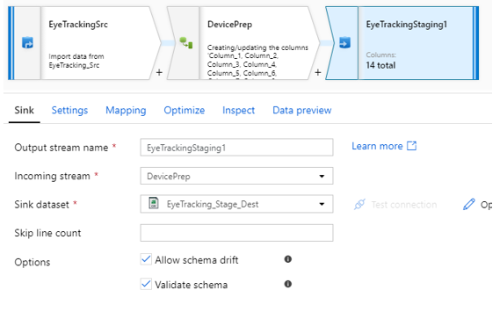
2) Sink
A. Output stream name : Sink를 저장하는 작업의 이름
B. Incoming stream : 이전에 작업된 내역 또는 Source
C. Sink Dataset : Datasets에 선언해 놓을 Set
D. Skip line count : 해당 수의 행만큼 작업을 진행하지 않음
E. Options
I. Allow schema drift : 컬럼 변경 허용
II. Validate schema : 선언된 schema를 찾을 수 없을 시 실패 처리
3) Settings
A. Clear the folder : 데이터 생성 시 해당 폴더 데이터를 지울지 여부
B. File name option : 파일을 분할 저장 여부
C. [Output to Single file] or [Pattern] : 저장될 파일의 이름 또는 분할하여 저장할 이름 패턴
D. Mapping : Schema Mapping 여부 지정
E. Optimize : 사용자가 데이터 흐름 형태를 선택 가능
(ex> round robin 등)
F. Inspect : 에상되는 결과값
G. Data preview : Data flow debug를 통한 사전 데이터 일부 조회
'Cloud > Azure' 카테고리의 다른 글
| Azure Databricks (0) | 2021.04.21 |
|---|---|
| Azure Data Factory - Linked Server 및 Trigger (0) | 2021.04.20 |
| Azure Data Factory - Datasets (0) | 2021.04.20 |
| Azure Data Factory - Pipeline (0) | 2021.04.19 |
| Azure Data Factory (ADF) 란? (0) | 2021.04.19 |








최근댓글