1. Linked Service
1) Data를 읽어오거나 저장하기 위한 저장소 연결 및 연결을 중개하거나 Pipeline을 가동하는 VM을 통틀어 칭함
2) Linked Service : RDBMS, File Storage, Rest API, Web등 데이터를 읽어오거나 저장할 저장소를 저장

3) Intergration runtime(이후 IR) :작업을 실행시킬 runtime용 VM

A. Azure IR
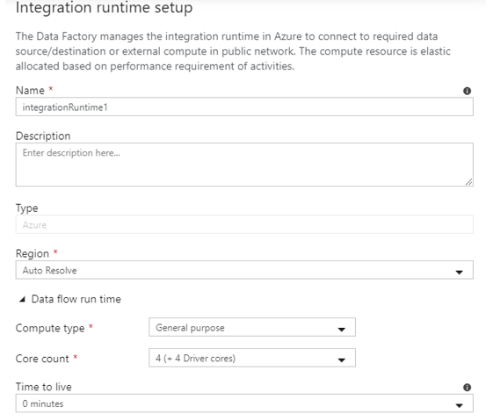
i. Azure에서 필요 시 자동으로 생성되었다가 삭제되는 컨테이너
ii. Name : IR명
iii. Description : IR 설명
iv. Type : Azure로 고정
v. Region : IR의 위치(Auto Resolve 시 ADF와 같은 Resion에 생성됨)
vi. Data Flow Runtime : Data Flow 사용 시 자동으로 생성될 컨테이너의 성능 크기 설정(Pipeline에서 설정과 값과 같이 설정됨)
B. Self-hosted IR :
i. 사용자가 이미 생성한 온프로미스 장비 또는 Azure VM을 이용하여 실행
ii. VPN을 이용한 사설IP로 보안 연결을 한다면 해당 IR을 필수로 이용해야 한다.
iii. 해당 VM의 퍼포먼스가 데이터를 가져올 때의 성능에 영향을 미침
iv. IR 설정

가) Setting
(ㄱ) Name : IR명칭
(ㄴ) Description : IR 설명
(ㄷ) Option 1: 자동으로 해당 IR에 연결되는 패키지를 다운로드 설치
(ㄹ) Option 2
① Step1 : IR구동 프로그램을 MS 제공 사이트에서 다운로드 설치;
② Step2 : Key를 IR과 수동 연결
(ㅁ) Node : 연결된 VM과 연결된 Pipeline 정보
(ㅂ) Auto update : IR프로그램 자동 업데이트 셋팅
① 업데이트와 스케줄이 중복 시 충돌이 발생되어 서비스에 영향이 있을 수 있다.
(ㅅ) Sharing : 다른 ADF에서 Linked Self-Hosted로 연결할 정보 및 연결ID
C. Linked Self-Hosted : 다른 ADF에서 사용중인 Self-Hosted IR을 이용
D. Azure-SSIS IR : 기존 MS에서 제공했던 Dataflow 시스템인 SSIS를 실행할 컨테이너
2. Triggers
1) Pipeline을 실행하는 Event 발생을 정의
2) Pipeline에서 Add Trigger로 생성 가능

3) 생성
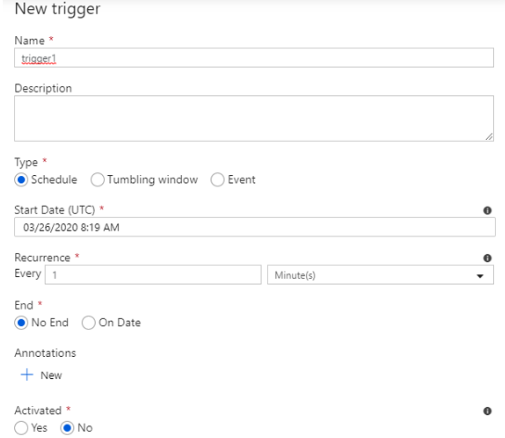
A. Name : Trigger 명
B. Description : Trigger 설명
C. Type
i. Schedule : 정해진 일정에 반복적인 실행
ii. Tumbling window : 정해진 일정에 반복적인 실행은 Schedule과 같으나 Option을 설정할 수 있고 변수를 처리할 수 있다.
가) Delay : 실행을 딜레이 시켜 실행 시작을 늦을 수 있다.
나) Max concurrency : 최대 동시 작업 수
다) Retry policy
(ㄱ) count : 재시도 횟수 제한
(ㄴ) interval in seconds : 재시도 시 몇 초 간격으로 재시도할 것인지 여부
iii. Event : Blob에 발생되는 생성 또는 삭제 시 발생
D. Start Data (UTC) : 해당 Trigger에 시작 시점, 시간 기준이 UTC라 각 지역에 따라 연산이 필요하다.
E. End : 해당 Trigger가 더 이상 작동하지 않을 시점
F. Activated : Trigger 사용 여부
'Cloud > Azure' 카테고리의 다른 글
| Azure Synapse Analytics SQL Pool에 Bulk Insert (0) | 2021.06.02 |
|---|---|
| Azure Databricks (0) | 2021.04.21 |
| Azure Data Factory - Data Flow (0) | 2021.04.20 |
| Azure Data Factory - Datasets (0) | 2021.04.20 |
| Azure Data Factory - Pipeline (0) | 2021.04.19 |








최근댓글